Panagiotis Christakakis

Resume | LinkedIn | GitHub | Google Scholar
Working as Research Assistant at CERTH - The Centre for Research & Technology
Currently pursuing two Master's degrees, one in Artificial Intelligence and Data Analytics at UoM and one in Robotics, STEAM and New Technologies in Education at IHU.
Thessaloniki, Central Macedonia, Greece
Portfolio
 Publications
Publications
Publications (Click to open)
Post-Heuristic Cancer Segmentation Refinement over MRI Images and Deep Learning Models
Authors: P Christakakis, E Protopapadakis
Journal: AI - MDPI
AI-based robotic trap for real-time insect detection, monitoring and population prediction
Authors: D Kapetas, P Christakakis, V Goglia, EM Pechlivani
Journal: IEEE Xplore (IPAS2025)
Aquaponic Farming with Advanced Decision Support System: Practical Implementation and Evaluation
Authors: EM Pechlivani, G Gkogkos, P Christakakis, D Kapetas, I Hadjigeorgiou, D Ioannidis
Journal: IEEE Xplore (IPAS2025)
AI-Driven Insect Detection, Real-Time Monitoring, and Population Forecasting in Greenhouses
Authors: D Kapetas, P Christakakis, S Faliagka, N Katsoulas, EM Pechlivani
Journal: AgriEngineering - MDPI
Comparative Evaluation of AI-Based Multi-Spectral Imaging and PCR-Based Assays for Early Detection of Botrytis cinerea Infection on Pepper Plants
Authors: D Kapetas, E Kalogeropoulou, P Christakakis, C Klaridopoulos, EM Pechlivani
Journal: Agriculture - MDPI
Vision Transformers in Optimization of AI-Based Early Detection of Botrytis cinerea
Authors: P Christakakis, N Giakoumoglou, D Kapetas, D Tzovaras, EM Pechlivani
Journal: AI - MDPI
Smartphone-Based Citizen Science Tool for Plant Disease and Insect Pest Detection Using Artificial Intelligence
Authors: P Christakakis, G Papadopoulou, G Mikos, N Kalogiannidis, D Ioannidis, D Tzovaras, EM Pechlivani
Journal: Technologies - MDPI
Early detection of Botrytis cinerea symptoms using deep learning multi-spectral image segmentation
Authors: N Giakoumoglou, E Kalogeropoulou, C Klaridopoulos, EM Pechlivani, P Christakakis, E Markellou, N Frangakis, D Tzovaras
Journal: Smart Agricultural Technology - Elsevier
Multi-spectral image Transformer descriptor classification combined with Molecular Tools for early detection of tomato grey mould
Authors: D Kapetas, E Kalogeropoulou, P Christakakis, C Klaridopoulos, EM Pechlivani
Journal: Smart Agricultural Technology - Elsevier
A Citizen Science Tool Based on an Energy Autonomous Embedded System with Environmental Sensors and Hyperspectral Imaging
Authors: CS Kouzinopoulos, EM Pechlivani, N Giakoumoglou, A Papaioannou, S Pemas, P Christakakis, D Ioannidis, D Tzovaras
Journal: Journal of Low Power Electronics and Applications - MDPI
 Personal Projects
Personal Projects
Projects (Click to open)
SmokersCollabFilter 🚬: Smoking Recommendations with Item-Item CF.
[still-in-progress💻🟢]
Smoking Recommendations with Item-Item CF: This is personal project of a collaborative filtering-based recommendation system focused on analyzing smoking habits and providing personalized recommendations.
What is a Collaborative filtering (CF) Recommendation System ❓
A Recommendation System is an algorithm that uses large amounts of data to suggest additional products to consumers, providing recommendations that are relevant to other users similar to them. The final results can be based on various criteria, such as previous purchases by other consumers, demographic information, etc.
Such recommendation systems are used by companies like Amazon and Netflix to make appropriate recommendations to their users, with the help of artificial intelligence since we are talking about a fairly large amount of data.
The Idea 💡
This idea came from our family business that I assisted in during my school and undergraduate years. For many years, my parents ran a kiosk in Thessaloniki. During my studies in the Department of Applied Informatics, I took the course “ Knowledge Discovery from Databases” in which we learned about item-item collaborative filtering techniques.
As a non-smoker, I found it interesting that often several of our clients would change cigarette or tobacco brands. Therefore, I thought about starting to collect data from specific customers on what cigarettes-tobaccos they have tried and how they would rate them in order to create such a system in the future.
Data Collection 📋 📲
Currently, I am implementing the Recommendation System I am trying to enrich the pre-existing data by using a questionnaire via Google Forms which is available here.
While we still ran the family business the collection of the necessary data was done with a simple questionnaire (in Greek) like the one below:
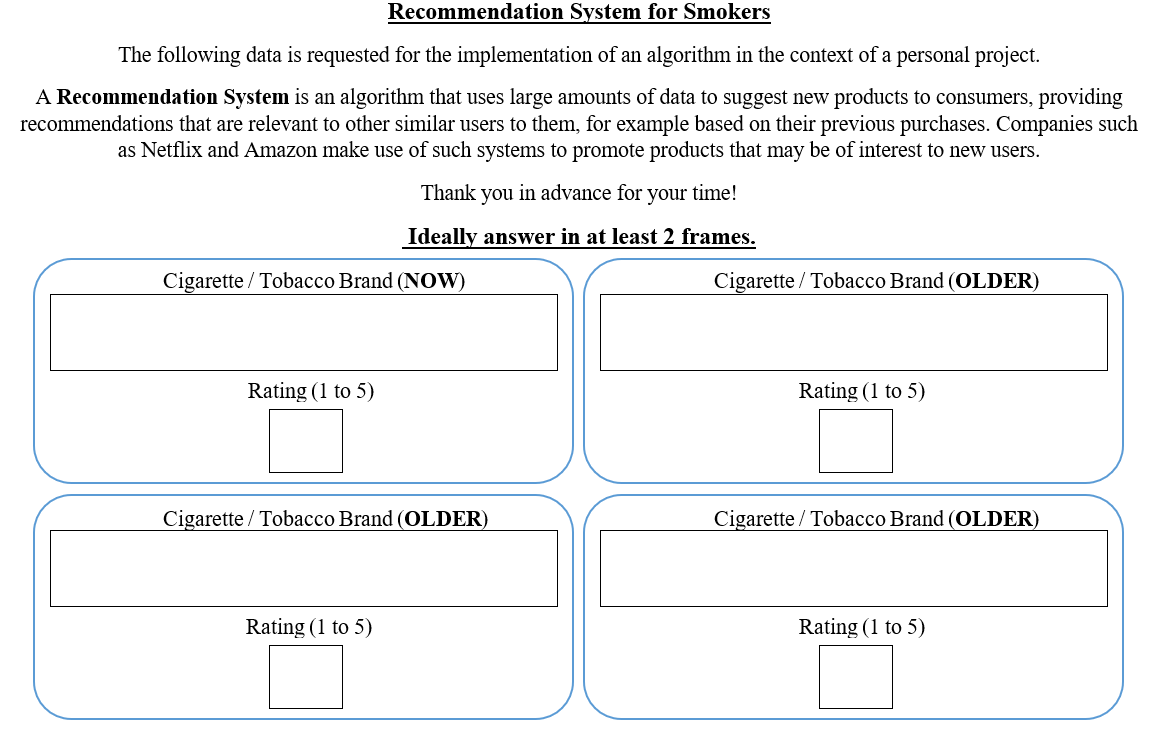
Additional Details 📌
The system leverages item-item collaborative filtering techniques to identify similarities between users based on their smoking history, ratings and preferences. By analyzing past smoking behaviors and user responses from questionnaires, the system generates recommendations for alternative smoking products. This project aims to offer insights into smoking patterns and assist users in making informed decisions towards new rated smoking products.
The final format of the table created from the answers of the questionnaires should look like this:
| User_1 | User_2 | User.. | User_N | |
|---|---|---|---|---|
| Tobacco Brand_1 | 4 | … | ||
| Tobacco Brand_2 | 1 | … | ||
| Tobacco Brand_3 | 3 | 5 | … | 4 |
| Tobacco Brand_.. | … | … | … | … |
| Tobacco Brand_M | 2 | … | 2 |
NOTE 🚭
Please do not embrace smoking, it is harmful to your health. This project focuses on analyzing smoking habits and providing recommendations, but it is important to note that the intention is not to promote smoking or encourage its use. Smoking poses significant health risks and can have detrimental effects on individuals and society. The aim of this project is to provide insights and support to individuals who may be seeking information related to smoking habits or alternatives. Prioritize your health and make informed decisions.
 Machine Learning
Machine Learning
Projects (Click to open)
Classification (Computer Vision - BoVW)
Classification using Computer Vision: Implemenation of Bag of Visual Words (BoVW) technique for an image dataset (Mammals Classication).
.jpg?raw=true)
.jpg?raw=true)
Chatbot
Building a simple chat-bot using Microsoft’s MetaLWOz dataset
Briefly, my implementation took into account:
• (1) Data pre-processing. Prepare the training data (pairs of sentences from the provided data set).
• (2) Neural Network Structure. Choosing an appropriate neural network structure that can model the problem.
• (3) Loss Function. Selecting an appropriate loss function.
• (4) Training. Training of the model on sentence pairs ([input, output]).
• (5) Testing - Inference. A txt as well as a gif are provided with some test conversations with the chatbot.

Unsupervised Learning (Clustering)
Unsupervised learning in Image Clustering: Develop and combine deep learning models / clustering techniques on Fashion-MNIST dataset.
Classification (Supervised Learning)
Simple Classification: Comparing different models on numerical data of financial indicators for businesses in order to classify them as bankrupt or not.
.jpg?raw=true)
.jpg?raw=true)
NLTK Library – Sentence Generator & Classify Reviews
NLP: Sentence creation from bigrams and trigrams generated by Project Gutenberg books. Classifier training to find positive and negative movie reviews.
CNN Architecture
CNNs: Comparing and seeking the best result of various convolutional neural network architectures for CIFAR-10 dataset, while trying different loss functions.
 Data Analysis with R
Data Analysis with R
Projects (Click to open)
Simple R functions - Dataset tidyr::who
R in simple use cases: Using the simplest R functions to transform the dataset into tidy format.
Simple R plots with ggplot2 - Datasets queen & mcdonalds
R in simple use cases combined with ggplot2: Plotting the simplest possible R plots. Dataset queen.csv contains characteristics for each song of the Queen albums as derived from Spotify. Mcdonalds.csv contains the price of Big-Mac in local currency for various countries and years. In general, this R Markdown contains Faceted ScatterPlots, BoxPlots, Histograms and BarPlots.
.jpg?raw=true)
.jpg?raw=true)
Rules, Correcting, Imputing with R - Dataset dirty_iris
Editrules, Correction and Imputing missing values with R: With the use of deducorrect, editrules and VIM the dataset is transofrmed into tidy. In general, this R Markdown contains numerical and caterogical rules, violations, hotdeck imputation and lastly some plots.
Visualization of the Olympic Games with R - Dataset results
Olympic Games with R: Dataset results.csv contains results of the track and field events of all the Olympic Games events until 2016. In general, this R Markdown contains the preprocessing steps as well as univariate and multivariate analysis, time series analysis techniques and interesting graphs for this dataset.
.jpg?raw=true)
.jpg?raw=true)
Interactive Maps with use of cshapes, leaflet and tmap (Dashboard Included) - Dataset world from cshapes
Using interactive maps with R: Manage and visualize geographic data with world datset from cshapes. This folder contains both R Markdown and Shiny Dashboard. Distance thresholds, buffer from capitals, distance from country’s centroid are included.
Graph plots and shortest paths (Dashboard Included) - Dataset world from cshapes
Network Data with R: Manage and visualize network data again with world datset from cshapes. This folder contains also both R Markdown and Shiny Dashboard. Directed graph of capitals and their distances, shortest path between capitals considering weight distance or total number of nodes are included.

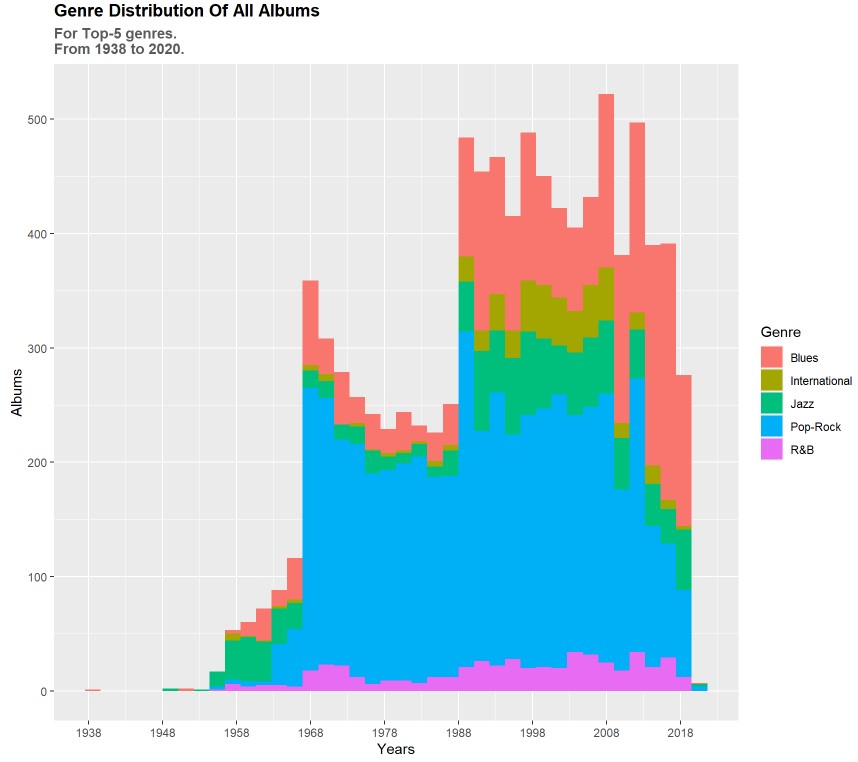
Interesting interactive visualizations (Dashboard Included) - Dataset album
The Dashboard is available for preview on my account on ShinyApps.
Music Albums Interactive Visualizations: Managing data about music albums, their genres, titles, year and artists.
Visualizations of NYPD shooting incidents (Dashboard Included) - Various Datasets
NYPD shooting incidents: Managing data about NYC shootings and trying to plot something interesting.
.jpg?raw=true)
.jpg?raw=true)
 Graph Networks Analysis
Graph Networks Analysis
Projects (Click to open)
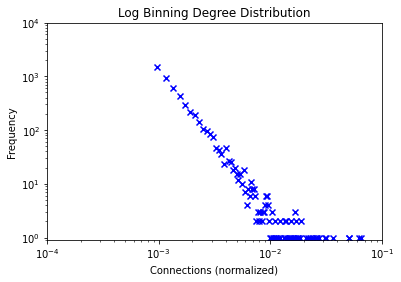
Production and Network Measurements
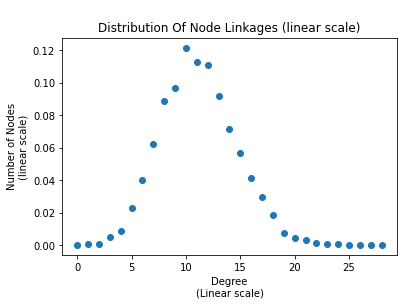
Production and Network Measurements: Studying and analyzing social networks. Comparison of the properties of the networks, commenting on the results and the parameter choices for the synthetic networks, and also the reasoning that was used to arrive at them. Finaly, plots are added and commented.
Community Detection Techniques
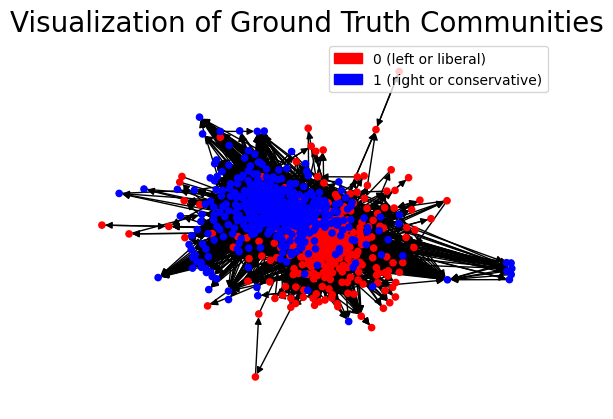
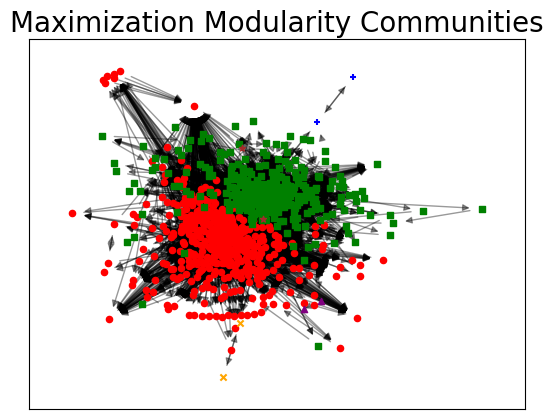
Detect communities with different techniques: Working with polblogs network, a directed graph from hyperlinks between blogs on US politics recorded in 2005 by Adamic and Glance, a comparison of the performance of different community detection techniques-algorithms is held, with respect to the ground-truth communities given.
.jpg)
Production and Evaluation of Node Embeddings
Production and evaluation of Node Embeddings: Working with polbooks network, a directed graph from Books about US Politics Dataset, we produce node embeddings using Node2Vec and then evaluate their performance using them for Link Prediction and K-Means Clustering, with respect to the ground-truth communities given.
.png)
.png)
Cypher Neo4j Queries
Data Insertion and Retrieval Queries using Neo4j: Data from an online lending library that records information about the books it has, its users-readers and the borrowing of books by users. The library provides search services for books to users as well as recommendations of books they may find interesting. At the same time, users are able to rate books and lists of the most popular and highest rated books can be provided to users. The online library uses a relational database to store and manage relevant information.
 Network Traffic-Flows Analysis
Network Traffic-Flows Analysis
Projects (Click to open)
Network Traffic Analysis in Data Centres
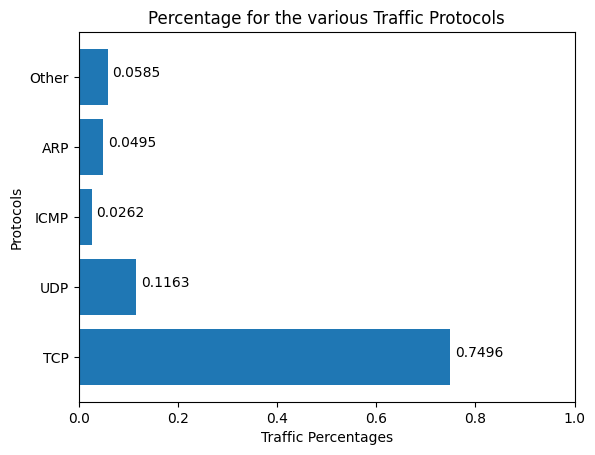
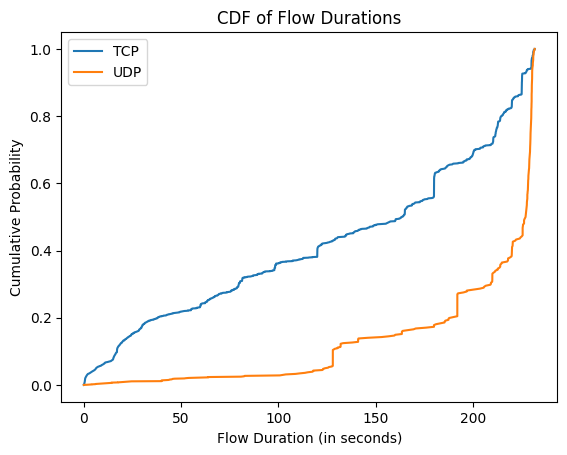
Network Traffic Analysis from PCAP file: Analyzing network traffic in data centers based on trace from PCAP file and extraction of traffic characteristics in the form of distributions. The extracted results are plotted in the form of distributions (e.g. CDF). For the implementation DPTK library is used.
Flow Migration Technique using OpenFlow
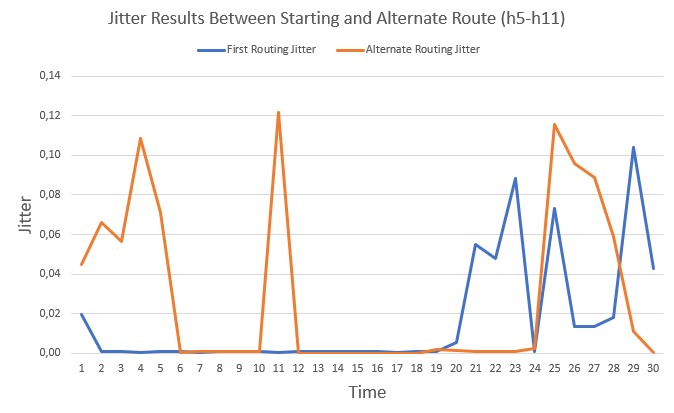
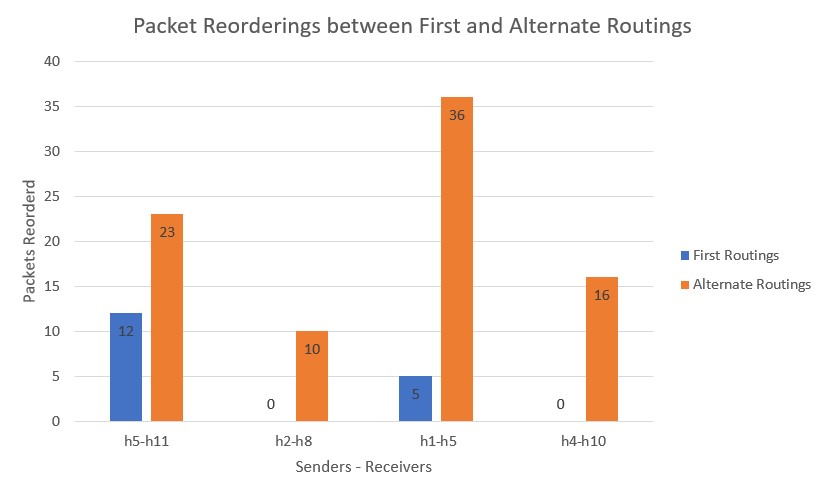
Flow Migration Technique: Implementation of a flow migration technique for transferring a network flow to another path of a network topology, while assessing any communication complications, such as increase in delay, packet loss and packet reordering. The flow transfers are done using OpenFlow and D-ITG.
 Computational Optimization
Computational Optimization
Projects (Click to open)
Compressed Sparse Row
CSR: Representation of a matrix A by three (one-dimensional) arrays, that respectively contain nonzero values, the extents of rows, and column indices.
Compressed Sparse Column
CSC: Representation of a matrix A by three (one-dimensional) arrays, that respectively contain nonzero values, the extents of columns, and row indices.
Equilibration (Scaling Technique)
Equilibration: Rows and columns of a matrix A are multiplied by positive scalars and these operations lead to non-zero numerical values of similar magnitude.
Arithmetic Mean (Scaling Technique)
Arithmetic Mean: This method aims to decrease the variance between the nonzero elements in the coefficient matrix A. Each row is divided by the arithmetic mean of the absolute value of the elements in that row and each column is divided by the arithmetic mean of the absolute value of the elements in that column.
Eliminate k-ton Equality Constraints (Presolve Method)
k-ton: Identifying and eliminating singleton, doubleton, tripleton, and more general k-ton equality constraints in order to reduce the size of the problem and discover whether a LP is unbounded or infeasible.
Exterior Point Simplex-type Algorithm
Exterior Point Algorithm: An implementation of Exterior Point Algorithm.
Parser for various TSP and more type of problems
TSP Parser: With the help of tsplib95 a complete parser was made to read instances of type TSP, HCP, ATSP, SOP, CVRP. Also it supports Edge_Weight_Types of EXPLICIT, EUC_2D, EUC_3D, XRAY1, XRAY2, GEO, ATT, UPPER_ROW, LOWER_ROW and many more. Main goal of this parser is to return important information about a selected problem in order to apply heuristics and metaheuristics later. It is important to mention that this work was part of a group project and my part was about Hamiltonian Cycle Problems (HCP). Contributors are mentioned inside the files.
TSP solver - Heuristic algorithm for optimal tour
TSP solver: With the help of elkai library and TSP parser from TSP Parser, Lin-Kernighan-Helsgaun heuristic algorithm is applied to HCP, TSP, ATSP, SOP files to find optimal tour and plot them.
CVRP solver - Finding routes and their weights
CVRP solver: With the help of VRPy python framework and TSP parser from code (6), best routes for CVRP files are found, as well as their weights.